I was recently tasked with copying a raw iSCSI LUN from one SAN to another within a window of an evenings downtime.
No problem I initially thought, I can present both LUNs to a single server and run an XCOPY/ROBOCOPY job to copy all of the data across. I later found there to be two problems with this plan:
- A copy job containing 7TB of data would not complete in one evening.
- There was a fairly large amount of files with long file names sporadically nestled in the file system which would cause the copy job to fail and require babysitting.
Solution
A colleague suggested that I could overcome the above issues by mirroring dynamic disks and then breaking the mirror once the synchronization had finished. That way users can still access the files via the source data whilst the disks are syncing and as it's done on a block level we no longer have to worry about any files with long files spoiling our fun.
First present both disks to a single server and convert the source to a dynamic disk:
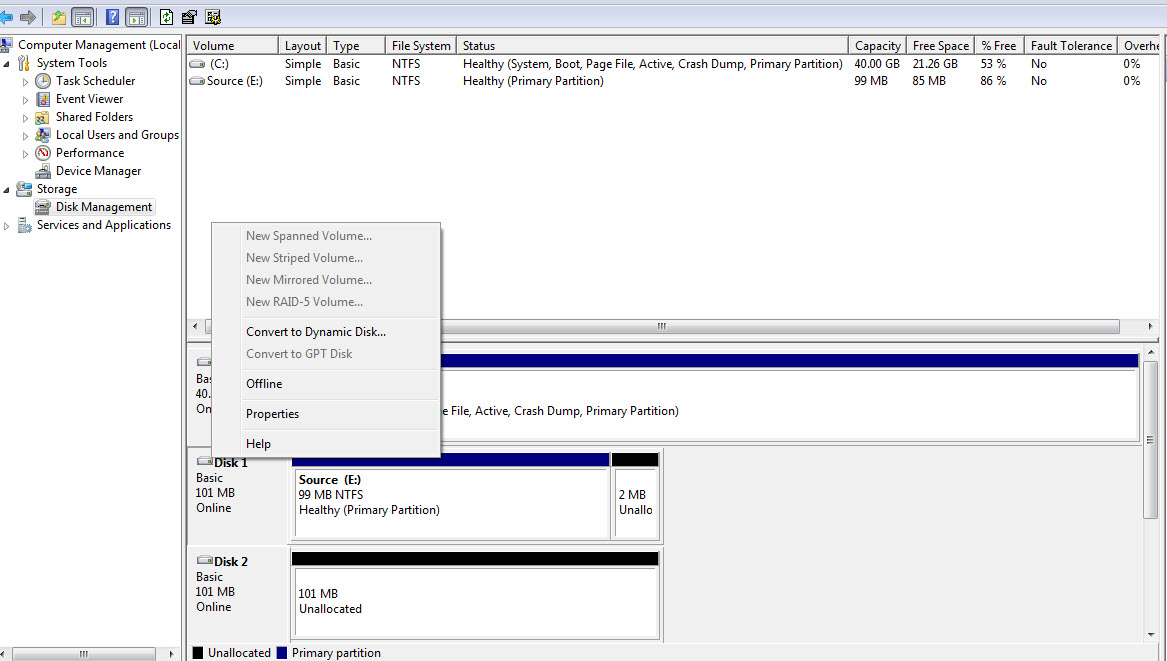
Right click the source volume and add a mirror:

Choose your target disk:

Accept that the target disk will be converted to a dynamic disk:

Wait until the disks have finished syncing and show healthy:

Right click one of the mirrored volumes and choose 'Break Mirrored Volume':

Offline the source disk and change the drive letter to resume that place of the source (in my example drive E:):

Disconnect the source disk and start using your new volume:

At the time of writing this I could not find this procedure documented online, so I hope it has been helpful to any of you reading.